Embedding visualizations turn high-dimensional data into 2D and 3D maps that let people see the shape of a corpus. But every map is a single, fixed perspective: the layout is dominated by whichever concepts the embedding model encodes most strongly. Different users come to the same data with different lenses — a literary scholar might care about emotion, a methodologist about which papers use machine learning — and a single default view rarely fits any one of them. Latent Manipulator is a system, built with Shivam Raval, lets users reshape an embedding visualization around concepts they care about, by amplifying or attenuating those concepts directly in the underlying embedding space.
The user describes a concept in plain language — "machine learning," "morality," "agency and control." A language model generates two contrastive sets of synthetic exemplars: a positive set that strongly expresses the concept, and a negative set that intentionally does not. Both sets are embedded with the same model used for the corpus (SentenceBERT in our case), and we estimate the concept direction as the mean-difference vector between them. This produces a unit vector in embedding space that captures the semantic axis the user described, without needing labelled data or model retraining.
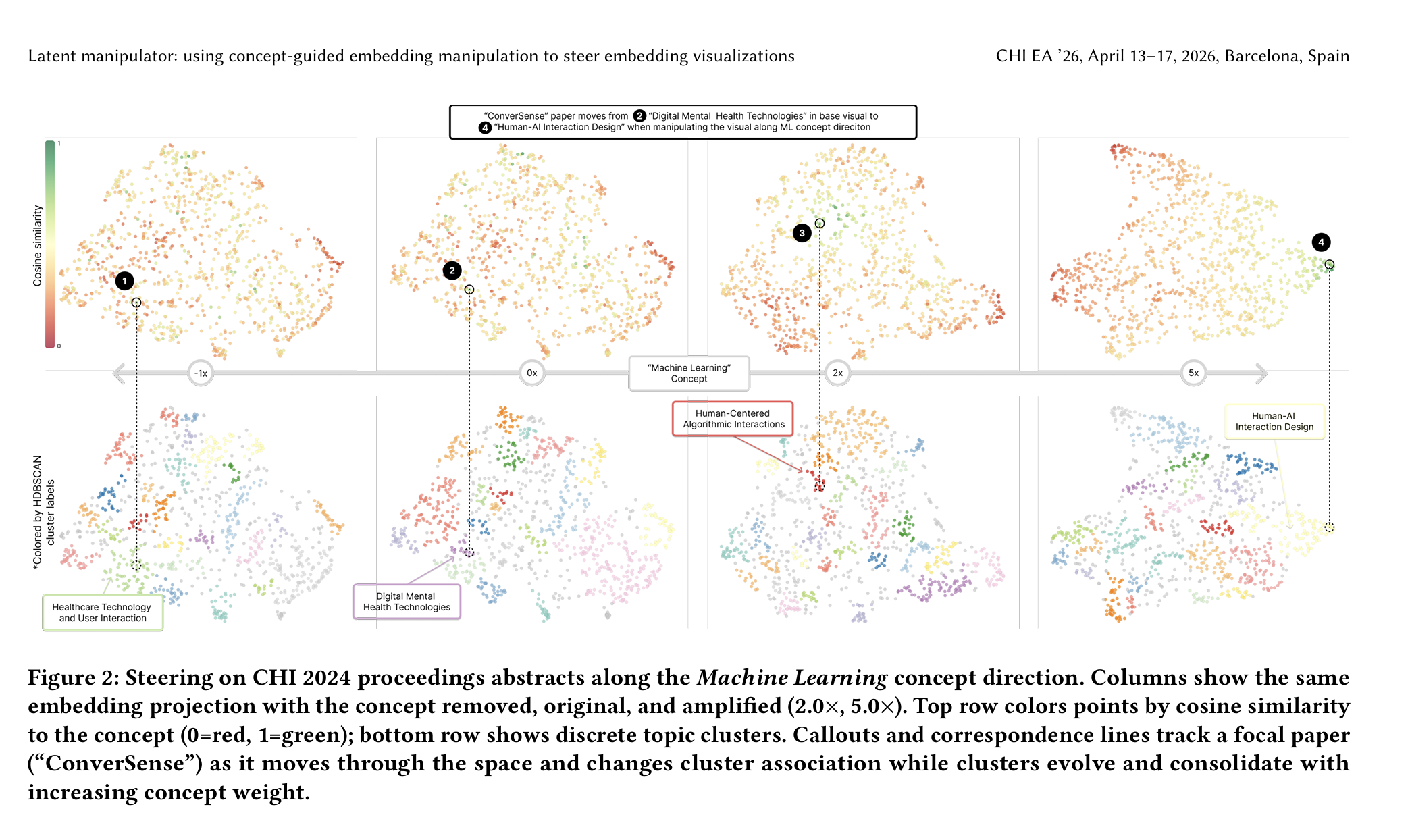
Each item's embedding is then reweighted along the concept direction by a user-controlled scalar α. Positive α amplifies the concept, pulling items together along that axis; negative α attenuates it; α = −1 removes the concept's linear contribution entirely. Unlike projection-based semantic axes, which collapse the visualization onto the chosen concept, this approach treats concepts as continuous filters: it adjusts how strongly one direction shapes the layout while preserving the structure induced by everything else. UMAP then projects the manipulated embeddings to 2D. Because the manipulation happens before dimensionality reduction, the visualization reorganizes around the concept rather than just recoloring it.
The interface wraps this method in a direct-manipulation loop. Users load a dataset, type a concept, and watch the map re-form as they drag a slider. A trail-recording mode tracks individual items as they move between regions, making the reorganization legible at the level of single papers or passages. A coloring mode shades each point by its cosine similarity to the active concept, so users can see not only where points end up but why.
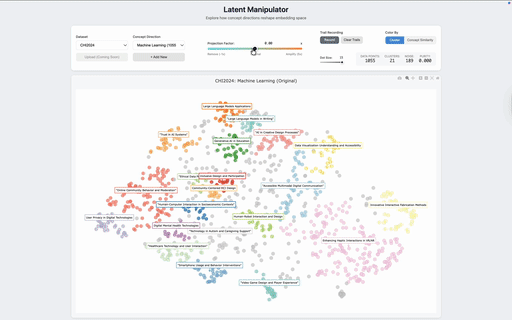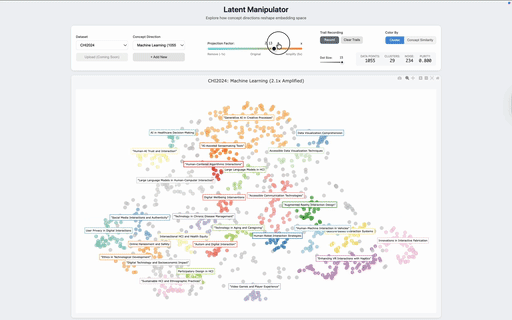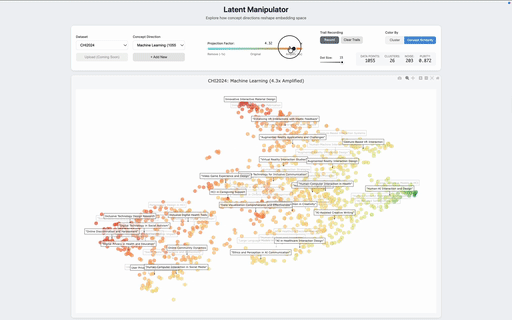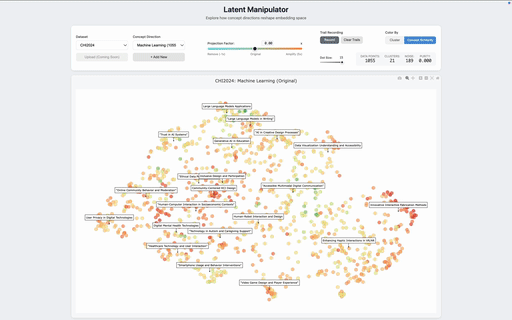
We tested the system on two corpora that surface different kinds of latent structure. The first is a collection of 1,055 CHI 2024 paper abstracts. In the default view, papers cluster by topical domain — generative AI in education, digital mental health, fabrication, and so on. Amplifying the Machine Learning concept reorganizes the same abstracts around methodological structure: ML-heavy contributions that were previously absorbed into application-area clusters migrate together, surfacing a layer of the corpus that is present in the data but invisible in the default view. The same data, asked a different question.
The second corpus is the full text of The Strange Case of Dr. Jekyll and Mr. Hyde, embedded at the sentence level. The default layout reflects plot and character. Amplifying Emotion re-knits affectively intense passages into a region we labeled Inner Turmoil and Fear; amplifying Morality surfaces an ethical structure — Duality and Moral Conflict, Inner Turmoil and Guilt — that exists across the text but is muted by the dominant narrative organization. The point is not that one view is more correct than another. It's that the same embeddings can support multiple equally valid organizations, and steerable manipulation lets readers choose which one to read against.
To check that this is more than visual rearrangement, we measured cluster purity along the targeted concept direction before and after manipulation. Across both datasets, purity increases with amplification — clusters in the manipulated view are more coherent along the dimension the user asked about than clusters in the default view. The method is doing real semantic reweighting, not just shuffling points.
Latent Manipulator is a step toward embedding visualization systems that support not just exploration of data but exploration of alternative organizations of the same data. It's a small intervention in the standard pipeline — manipulate embeddings before projecting, rather than treating the embedding space as fixed — that opens up a much larger interaction surface. The work was published as a Late-Breaking Work at CHI 2026 in Barcelona, and builds directly on the embedding-visualization platform I developed in Latent Lab.
Publications
- Latent Manipulator: Steerable embedding visualization through concept-guided manipulation
April 2026 · CHI Extended Abstracts (Late-Breaking Work)